
The term AI revolution has for some time now, reached the general media and this is largely due to two advancements in Artificial intelligence. The first one was marked by the 4-1 victory of Alpha Go in its series of five games against the Corean Grandmaster Lee Sedol, in 2016. Since the game of Go is considered more complex than chess (the number of possible configurations on a go board is larger than the number of atoms in the known universe), this event reached the headlines across the globe. The second one was in the domain of Natural Language Processing, or NLP, that came into worldwide spotlight with the launch of the GPT-3 engine in 2020, capable of generating, summarising text as well as question answering.
The later is due to many factors. The Economist has listed three of them: advancements in algorithms, more powerful computers and the availability of large datasets. This blog post aims at explaining the notion of attention in deep learning, which is responsible for the first of the three factors listed by The Economist: the algorithm advancements. We want to present this revolutionary notion to a general public and not only to machine learning experts.
The notion of attention in NLP originated in 2016 with Dzmitry Bahdanau’s paper “NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE“ and was first used in Neural Machine Translation.
To illustrate how it works, I will refer to a fragment from Jaroslav Hasek’s book The Good Soldier Svejk, where Svejk is detained as a deserter. He has three soldiers guarding him, a Hungarian, a German and a Czech.
“The Hungarian talked with the German in a peculiar way, because the only words he knew in German were Jawohl and Was? When the German explained something to him, the Hungarian nodded his head and said: <<Jawohl>>, and when the German stopped talking the Hungarian said <<Was?>> and the German started again.”
Can an AI system do better than Hungarian guard and give better one word answers to questions? I trained a question answering model consisting in a recurrent neural network with an attention mechanism.
When training a neural network, the system finds the optimal values of some numbers, called weights, that are saved and when the model is used for prediction, these weights, in the form of matrices, are multiplied with the numerical values of the input. The recurrent layer allows us to feed an entire sentence, a question in our case, and the weight for each word also depends on the weight of the preceding word.
The attention mechanism is a neural network hidden inside this neural network used to predict the answer, which learns the most important input words and where to pay more attention during each prediction.
This process becomes clar when we check some results. For the question “Am I a human?” the system answers “No”. To decide if the system’s answer is correct or not is a philosophical matter, but notice that the attention is focused on the second part of the question. From a grammar point of view, most of the focus is on the complement human.

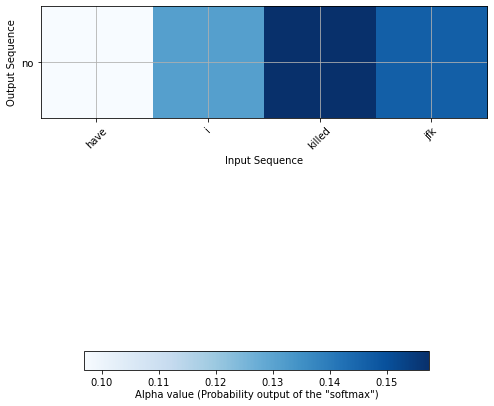
For the input “Have I killed JFK?” the answer is again negative. This is true since I wasn’t born yet in 1963, but we can one more time, notice the attention focused on the complement and on a more general perspective, on the second part of the question.
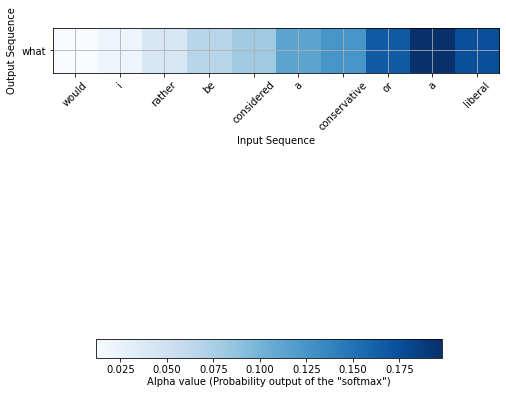
If we feed a longer question like “Would I rather be considered a conservative or a liberal?” the answer is “What?” and the attention is focused on the second half of the question.
The go communities have benefited from the set of games Alpha Go vs Lee Sedol, because the system played some moves that no human have ever played. Just like the go players learned from the AI, we can also learn real life lessons from the question answering model with attention.
If one wants to be able to give one word answers in a conversation, but without paying full attention to the conversation partner, from the conclusions regarding our attention model, it follows that that person can simply do the following:
- If the question is long, answering “What?” is quite safe
- It is enough to pay attention to the second part of a question to locate the complement.
Following these two advices, the person would be doing a much better job than Svejk’s Hungarian guard.
The second concept of attention is the Self Attention developed in 2017, in the paper Attention is all you need, by a group of Google Brain researchers.
This is a totally different concept than the above described attention and it serves a completely different purpose. The former manages the attention on a sequence of inputs while self attention is encoding words by vectors in such a way that the encoding encapsulates the semantics of the word that was not achieved by the concept of word embeddings that was previously used for such an encoding. It means that the same word has different representations in different parts of the text or in different contexts. In a more technical description, it uses a query-key-value framework that we want to illustrate below. In order to to this, we took three verses from songs, all of them containing seven words, all containing the word sky.
- Excuse me while I kissed the sky from the song Purple Haze by Jimi Hendrix
- You look up to the night sky from the song The sky is a neighbourhood by Foo Fighters (in fact from an interview regarding the song)
- (There) is an airplane up in the sky from the song Goodbye, blue sky by Pink Floyd
All three of them contain the word Sky, in different contexts. We want to derive a representation of this word for each of the three sentences. To do this, let’s take the first example and for each word (except sky), ask how much that word is an answer to the question Why? (the query) in relation to the word sky, on a scale from 0 to 1. I would rate as following:
- Excuse: 0.2 (A small value, since it answers the question What, but one should excuse me and not the sky)
- me: 0
- while: 0
- I: 0
- kissed: 0.8 (What I did? I kissed the sky)
- the: 0
We can visually represent these values below (the stronger the color, the greater the value):
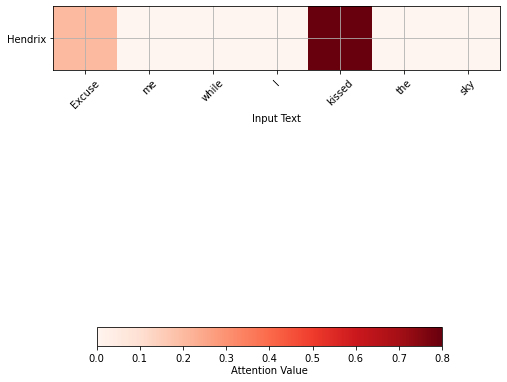
This is precisely what we wanted to have, a representation of the word sky, and is called a one head (self) attention. We can continue with different questions and putting the results together to get what is called a multihead attention. In our case, we will also ask where and when, but when implementing the algorithm, the computer does this implicitly, it finds queries that are not necessarily intelligible to humans. We will get for Hendrix:
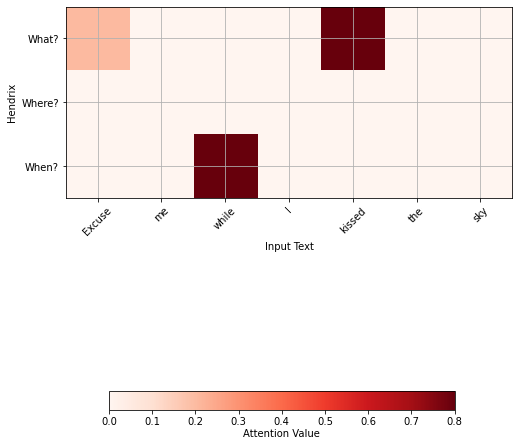
For the words sky in the Foo Fighters example:
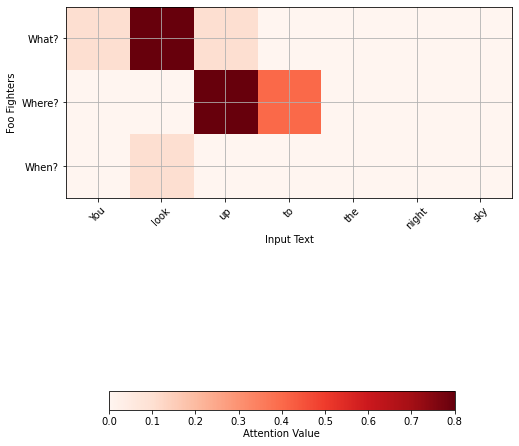
And finally, for Pink Floyd:
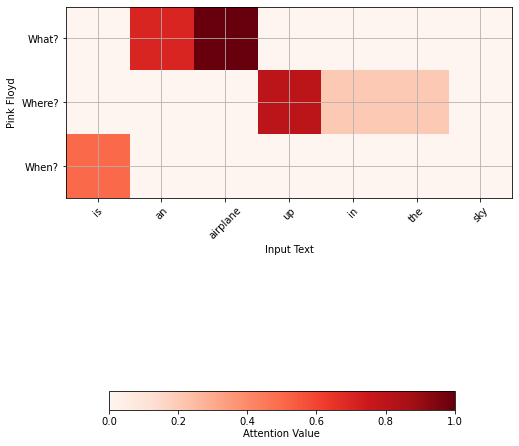
Let’s notice that the good soldier Svejk would greatly benefit from the multihead attention. He often took words in the literal sense, for example:
“He gave Svejk a bloodthirsty look and said:
‘Take that idiotic expression off your face.’
‘I can’t help it’, replied Svejk solemnly. ‘I was discharged from the army for idiocy and officially certified by a special commission as an idiot’ “
However, he might take the multihead term literally, and consider that he needs multiple physical heads to use it.
At NEXiT we leverage AI to help businesses improving their products and operations. We deliver concrete benefits to our customers in the field of recommender systems (User privacy, Context Sensitive) and forecasting solutions.