
The digital era changed the way we relate to information. Everything we want is at a few clicks distance and no one can deny that this is a good thing, but like any good thing, having it in excess is problematic. If one wants to buy an electronic device, read a book or go to a restaurant, there are simply too many options. The recommender systems are intelligent algorithms that filter all this information and only keeps the results which are relevant to each user, according to his preferences. However, in the context of user privacy, using demographic or personal data is no longer a good option, so nowadays, the filtering is done only by anonymously matching the user behaviour with other users. This is called collaborative filtering.
We investigated how the most popular collaborative algorithms compare and by doing so we found some analogies in mythology and classical literature. This is no wonder, since the oracle institution was central to the ancient greek culture. Apollo’s temple at Delphi was considered the centre of the world, and the oracle there was Pythia, the temple’s priestess. A pure coincidence is that her name is related to the giant serpent Python who was slain by Apollo, that is also the name of the programming language that is the lingua franca for Machine Learning and so all the artificial intelligence algorithms are developed in Python.
The two most popular collaborative filtering approaches are the K-nearest neighbors (KNN) and the Singular Value Decomposition (SVD). Both can be explained in term of real life actions and have existed since the antiquity.
The KNN works like this: let’s say a user U has never rated an item I . The algorithm tells us how U would like I by choosing the k number of users which are more similar to U in their preferences and which have rated the item I, then average those ratings. It is like asking out friends if they liked a movie and go to see it only if most of them liked it. Homer has a good example of it. On the island of Aeaea, Odysseus managed to outwit Circe the enchantress who had transformed his companions into pigs, and make her turn them back into humans. After that, they fall in love and have children but one year later, Odysseus took the decision to leave, following a KNN approach: he follows the advice of his companions.
The KNN algorithm is even more obvious in Spielberg’s 2002 sci-fi film Minority Report. The action takes place in the year 2054, where the officers of a Police Division called Precrime are arresting criminals before the crime happens, based on the predictions of three persons with special powers called precogs. We have a 3-nearest neighbours recommender system providing recommendations of who shall be arrested.
The SVD is more complex. Imagine that we want to estimate the preference of U for the item I, where the item is a dish in a restaurant. When the dish is an abstract name in the menu, U will ask the waiter about the characteristics of the dish: if it contains meat or not, the type of meat, maybe if it is rare, medium or well done, and also calories, fats and nutrition facts. All these characteristics are called features in machine learning. The user matches the features described by the waiter with his own preferences and they act together as a recommender system. SVD brings this a whole level further, by making the algorithm construct features that make no sense for a human and usually cannot be understood and interpreted by us. We can have, for example, a numeric feature representing the amount of brown in a picture of the dish that encode how nourishing the dish is and a proportion of contrasting colors encoding the style of the plating, or how instagrammable the plate is. These are called latent features.
This SVD also appeared in antiquity. Herodotus tell the story of Croesus, the king of Lydia. When The Median Empire has united with the Persians under Cyrus, they became a threat to Lydia. Croesus asks Pythia, the priestess of Delphi if they should go to war with Persia, and the oracle’s response was that if he goes to war, a great empire will fall. Then he askes again if he will reign for many years as the king of Lydia. Pythia answered “When a mule becomes leader of the Mede, then, oh Lord, it is time to flee“.
Croesus goes to war thinking that the Persian empire will fall , loses the campaign and the Lydian empire vanishes from history. The great empire who have fallen was the Lydian and the Persian king Cyrus was of mixed origin , his mother was of Mede origin and his father was Persian, just like a mule is half horse, half donkey.
Let’s notice that the oracle of Delphi acted exactly like the SVD. To answer if Croesus will win the war, instead of using features that made sense for a human, like the size of the armies or weapon quality, it constructs the latent binary feature of the opponent’s origin, if it is mixed or not.
Choosing between two machine learning algorithms, is usually a straightforward task, the most accurate algorithm is chosen. However, in the particular case of recommender systems, things are not at all straightforward and never were. In the context of the Trojan war, Cassandra gave some very precise recommendations such as not allowing Helen to enter Troy and marry Paris, because that would bring the end of their city or not letting the Trojan Horse in, because Greek soldiers are hidden inside. Cassandra acted like a very precise recommender system with no value for the Trojans. Getting back in the present, even if a user is trusting a recommender system, the system might not bring business value no matter how precise is it. For example, in an online grocery store, a system recommending bread to a user would be very accurate with almost zero value, since the user would most likely buy bread anyway.
Of course, we do want from a recommender system to be accurate, but there are more characteristics that we want from it and sometimes these characteristics are in contradiction with the accuracy. In the Gareth Jennings 2005 film The Hitchhiker’s Guide to the Galaxy, the supercomputer Deep Thought is asked the ultimate question of life, the universe and everything. It seems that we could not use Deep Thought as a recommender system, because the answer of the ultimate question is 42. The amount of items that ended to be recommended is called coverage and Deep Thought had quite a bad one.
We compared the two approaches on three datasets: Movielens, Netflix and Wikoti. The results are represented in the graph below, where the width of the bar is proportional to the dataset size (yes, Netflix is enormous in comparison with the other two), the hottest the color, the greater the precision and the height of the bar represents the coverage.
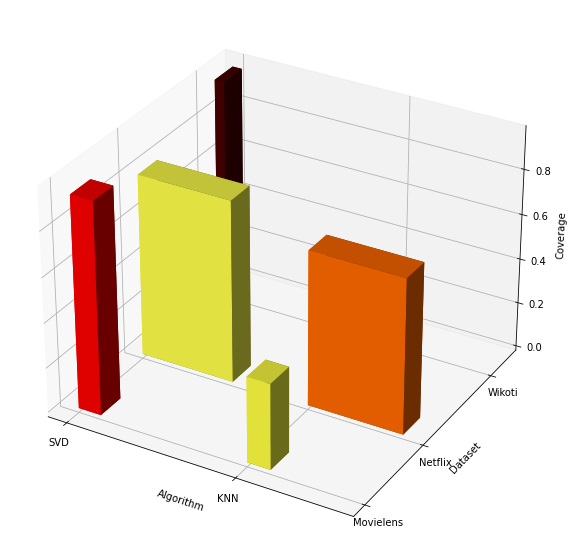
One might simply say that SVD is better, but let’s have a closer look. In terms of precision, for the SVD, the smaller the dataset, the greater the precision, because SVD is harder to train and tune on a very big dataset. The only case in which KNN gives better results is for the large Netflix dataset. In terms of coverage, SVD is better in any case.
Let’s see if we ca draw some real life lesson from this. We have a problem or a question and have two options to sort it out: analysing it and try to find the best fitting solution is this way, or we ask some friends how would they sort it out. Usually, it’s better to analyse, except when the problem is complex. For example, if we go out with some friends and ask them for a nice dinner place with live music in a small town we have more precise options if we analyse what type of food and music we prefer (SVD) but in New York, asking them where to go would provide precise answers with less coverage in any case.
Let’s also notice that the fact that on a small dataset, KNN is precise but with a really bad coverage is really what would we expect. If we live in a small town and ask our friends for a good place to eat, they will probably mention the same restaurant.
The serendipity measures the amount of surprising recommendations, which are items that U would like but did not expect to find. We also know it from the antiquity. Athena asks Zeus how can the city of Athens be saved from the Persian attack, and the reply was “a wall of wood alone shall be uncaptured, a boon to you and your children“. This was unexpected because in those times, the fate of a war was decided on land, but indeed, the greeks won the naval battle of Salamis with their trireme ships forming a wall of wood.
The graph below is similar to the first one, but with serendipity instead of coverage.
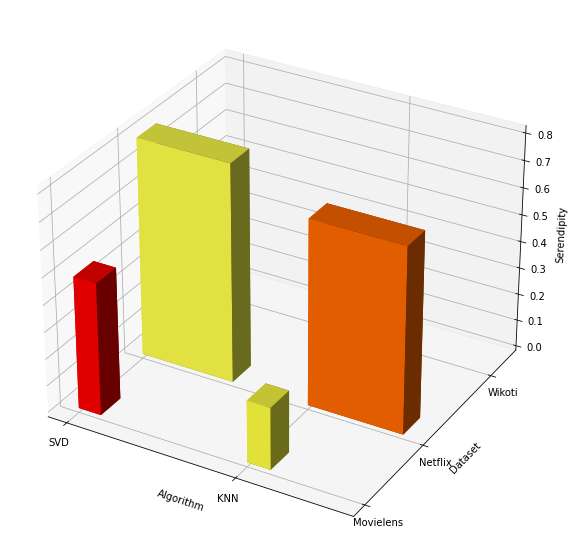
Again, SVD is better than the KNN but clearly serendipity depends more on the dataset size than on the algorithm. For wikoti, which is the smallest dataset, the bars are not even visible. The more complex the dataset is, the greater the serendipity. This is again something to be expected: we have better chances to discover an unknown great band playing in a bar in London that in a small town.
All of the above remarks, help us choosing an approach. For example, in The Iliad, Patroclus tells Achilles to join the greek forces in the Trojan war. In doing so, he acts like a 1-nearest neighbour recommender system for Achilles, who rejects Patroclus offer, but gives him his armor. Wearing it, Patroclus is killed by Hector, but manages to drive the Trojans back to the city.
For the same decision, Thetis, who is Achilles mother, acted like a SVD: “For my mother the goddess, silver-footed Thetis, tells me that twofold fates are bearing me toward the doom of death: if I abide here and play my part in the siege of Troy, then lost is my home-return, but my renown shall be imperishable; but if I return home to my dear native land, lost then is my glorious renown, yet shall my life long endure, neither shall the doom of death come soon upon me.” Basically, she takes two features, her son’s life and his glory and does an analysis by matches them with what Achilles needs. The problem itself is not complicated, Achilles was upset by Agamemnon and no longer wants to fight. SVD worked better in this case.
It is not the case in one of the most iconic scenes from The Matrix trilogy, in which Morpheus acts like a 1-nearest neighbour for Neo, recommending him the choice of two pills: the blue pill, making Neo return living in his simulated reality like nothing happened, or the red pill which allowed Neo to learn the truth about what The Matrix is. However, the Slovenian philosopher and psychoanalyst Slavoj Zizek, in his 2006 documentary A Pervert’s Guide to Cinema, is SVD-analysing the problem by saying that the choice between the blue and the red pill is not a choice between illusion and reality, because The Matrix is a fiction that already regulates reality and so, by removing the fiction, one also loses the reality, and therefore the need for a third pill, one that reveals not the reality behind the illusion, but the reality in the illusion itself, namely if something is too traumatic, we have to fictionalise it and in this sense, any illusion is real. Zizek’s SVD coverage of three pills is better than the original KNN of two pills and this third pill is a serendipitous solution.
It turns out that choosing between algorithms for a recommender system is a complex problem with no straightforward solution, as the greeks already knew. At the entrance to the Apollo’s temple at Delphi, where the oracle was, three frases were displayed:
- Know thyself
- Nothing in excess
- Surety brings ruin
The first two of these maxims are similar to using machine learning algorithms: they have to be trained on past data (know thyself) and one of the worst defects of a ML system is when the algorithm learns too well the training data and loses the ability to properly predict the future. It is called overfitting and it matches the second maxim.
The last one seems to match our analysis, the precision itself is not enough to chose an approach.
While SVD is better overall, it seems a good idea to have in place several recommender system algorithms, because choosing one largely depends on the problem.
However, this blog post covers half of the problem, because recommendations also depends on the context and moreover, different approaches might suit better different users and this is where the future of the digital recommendations is.